What’s a stock master?
It’s database, that contains data on stocks. It is also the master or authoritative, at least for me, source of that data. What kind of data exactly? Prices and fundamentals (and maybe economic time series).
This post is going to document the data sources and tools used in building this database. The repo for the project is here.
Motivation
Firstly, why do I need a database that containing this type of information?
A couple of my earlier posts alluded to the fact that I have an interest in modeling stock prices. For that I require clean data in a consistent format. Grabbing data ad-hoc from the internet doesn’t cut it for my use case. While downloading a couple of tickers on the fly works for a blog post or proof of concept, it won’t cut it for serious analysis. I need a persistent storage, from which I can quickly grab data for analysis using say, R or Python.
Secondly, acquired data will need to be transformed. One such transformation is that of the frequency of the data. Different sources of data are collected at differing periodicity. Price data has a daily periodicity, fundamental quarterly and economic time series monthly. Analysis will be performed monthly. Transformations will also take as inputs relations between stocks in the cross section. Which stocks are in the top decile of ROA, the bottom prior 3 month return quintile, for example. Not something easily done with data stored across hundreds of csv’s1.
Specific requirements
Breadth of data
I will need data on many stocks. The analysis I plan on doing will look at how stocks behave in the cross section. I’ll be looking to answer questions such as, do undervalued stocks outperform when the economy improves? This means having data on a thousand or so stocks. Why so many? It is only after comparing valuation (or any other metric) across a large sample that the concept of under or over valuation can be estimated. This means defining a universe of stocks and finding a way to acquire and store data efficiently at scale.
Cleansing
I’m under no illusions that the raw data landed into the database will initially be in a usable format. Post acquisition, a validation and cleaning process will need to be employed before any of the transforms I mention above are performed.
Automated
Lastly, I don’t want to be spending hours updating my database with new data. The fun is in the analysis, not the data acquisition. The process of ingesting data should be pain free and repeatable.
In summary I want a ready source of clean data that is updated easily, and that is in a format suitable for further analysis.
In what follows, I will document the sources of data and how that data is captured and initially verified. We will look at the database data model, and I’ll also outline some of the issues encountered along the way.
Let’s get started with the data.
Data sources
Fundamental data is sourced from the Securities and Exchange Commission (“SEC”) website. Price data is from the Alpha Vantage API.2
Fundamental data
All stocks issuing securities to the public in the US are required to file financial statements with the SEC. The SEC stores this data in the EDGAR (Electronic Data Gathering, Analysis, and Retrieval system) database. The SEC (specifically the Division of Economic and Risk Analysis Office) makes this data available in an aggregated format via its website each quarter. A zip file is exposed which contains filings for that quarter. The zip contains four text files:
| File | Description |
|---|---|
| SUB | Submission data set, includes fields of information pertinent to the submission and the filing entity |
| NUM | The Number data set includes, for every submission, for each primary financial statement as it is rendered by the SEC Viewer/Previewer, all line item values |
| TAG | Tag data set; includes defining information about each tag |
| PRE | Presentation data set; this provides information about how the tags and numbers were presented in the primary financial statements |
The data dictionary is here, and provides much more detail.
That reads like the data is all very orderly and structured. You might think that once this data is landed into a database, analysis would be straightforward. Financial statements are by definition structured in the sense that the underlying data is stored in a general ledger. General ledgers conform to double entry bookkeeping concepts. Surely the SEC enforces some kind of standardisation in the presentation of filings submitted.
Wrong! And that is not an opinion I hold on my own.
Something as simple as consistently capturing headline balances like cash or shares outstanding can prove very difficult as we will see.
Price data
Fortunately this is a little easier. Alpha Vantage provides a free API for collecting time series of stock market price and volume data. Data is exposed in CSV or JSON format and is written directly to the database.
Tools
The database
I’m using PostgreSQL as the database engine. After all, it is (albeit self proclaimed) the world’s most advanced open source relational database. Other options include open source databases such as MySQL or MariaDB. There are also time series specific databases such as Timescale. They all would have done the job. PostgreSQL seems to have a good community and support, so that it is.
I am using dbeaver to work with the database.
Data acquisition
I’m using Python to grab the data described above. The “modis operandi” is to read the required data into a data frame, reshape if required, connect to the database, and then write to the database. This is of course performed in a loop to allow multiple quarters (in the case of the SEC data), and multiple stocks to be loaded at once. I’m using the standard libraries you’d expect for these types of operations. SQLAlchemy, psycopg2, pandas and Requests. The work flow sounds fairly simple and straightforward, however a lot of development went in to making this work. What follows is a non exhaustive list of issues / challenges encountered:
The SEC data is held out to be UTF-8 encoded. Non UTF-8 characters are found in the PRE file, this necessitates building logic to select the correct encoding
Opening a zip file is not quiet as easy as
read_csv(). Time to get familiar with the io and zipfile modulesWriting to a database with pandas
to_sqlis very convenient but also very slow. I will be looking to replace this with psycopg2’scopy_fromfunction, saving the data frame as a csv in memory and then writing to the databaseAlpha Vantage gives us the option of various download types, full or compact versions. These need to be selected dependent on whether a stock has had a split since last updated
The Alpha Vantage (free version) API has download restrictions. Maximum API calls per minute and per day. Rules have been included to limit calls based on these restrictions
Encoding logic to grab new data only. This entails getting the date of the most recent records in the database, and determining how much data needs to sourced and written to the database
Quite a bit going on. Keep in mind that starting out, I lot of these tools were new to me. Some of the issues I have encountered are reflective of a steep learning curve. All the same, this can be a messy process and it takes time to make it work.
The script pulling this data is copied below.
Data cleaning
Fundamental data
The SEC data is in a long format whereby the key to the NUM file is date, company id and financial statement line item. Pretty much every balance on the financial statements is present. As I said above, those balances are not necessarily standardised. A lot are not required and sometime they are missing. We therefore need to map records to a standardised template. We also need to ensure the integrity of balances returned (a balance sheet needs to balance).
Lets look at those two things in turn.
Mapping line items to a standardised template
The concept here is simple. A reference table has been created which maps financial statement line items to standardised categories.3
For example, some filers label cash balances CashEquivalentsAtCarryingValue, others CashAndCashEquivalentsAtCarryingValue. Both of these map to cash and this process works for the most part. It can be problematic however when tags overlap. For example one filer may disclose both TotalCash and TotalCashandEquivalents (lets call it Company A), and another only TotalCash (Company B). Both of these tags need to map into cash but which to choose? If you sum these records Company A will be overstated, a component of the total will be added to the total. If you exclude TotalCash from the mapping , Company B will have no cash balances mapped to the standardised template. I have taken the record containing the largest balance to get around this problem. Other types of balances require taking the minimum. To add to the complexity, the use of maximum or minimum may be dependent on other rules and constraints. See below.
Ensuring integrity of accounting information
A balance sheet needs to balance. Net income implicit in the movement of retained earnings during a period must agree to the income statement. The components of a summary balance (current assets for example) must sum to that summary balance. There are many other “accounting identities” that when violated indicate bad data. These represent constraints on certain balances, and these constraints can be used as rules for determining appropriate balances when data is missing or inconsistent. There exists a hierarchy to these accounting identities corresponding to the granularity at which financial statements are presented. For example at the highest level, assets equals liabilities plus equity. At a lower level, the goodwill amortisation charge in the income statement should correspond to the movement in accumulated amortisation in the balance sheet. The level at which a constraint is defined is important for the order in which we assess it.
OK, that’s all fine and good. What is the impact on how we actually check integrity and implement transformations if required?
To start with, what we don’t do is aggregate low level balances to determine summary or total balances. This does not work due to the variation in labels discussed above.
Rather, accounting identities are checked at the highest aggregation level, and then only once this has been verified are balances at the next lowest level of granularity considered. We peel back the onion so to speak. Lock in what we know to be true, and then dig deeper. It is much more likely that higher level balances like total equity are present and correct, than lower level balances like receivables.
To put that in real terms, imagine a case with no total assets returned (some companies will present current assets and non-current assets but not total assets). We therefore look at total equity and total liabilities to infer total assets. The next round of verification is at a lower level of granularity, and it is then that current assets and non-current assets are summed to check against total assets.
This process is implemented in a view which is quiet the monster, I’ve included it below to get a flavour of what is required here. The never ending series of CTE’s is checking if internal consistency is satisfied, if not, finding the missing balance, and then choosing the method to infer what is missing.
Price data
No cleaning is performed on price data. It is hard to know if something is not right without the reference points accounting identities provide. It is worth pointing out the update method. Data is appended when historical prices change due to dividends or splits. Most applications would overwrite historical data in this scenario. I choose not to do this. I want to make sure I don’t lose data should Alpha Vantage ever decide to provide less than 20 years of history. This requires that when querying price, only the most recent acquisition data is retrieved so that multiple records relating to the same date are not returned.
Data model
The database can be characterised as an analytic database, ingesting raw data requiring transformation.
The data I am storing comes in different grains, relating to the frequency of that data. Stock prices are daily. Fundamental data is quarterly. Reference data (stock symbols, stock names, universe membership, etc) is slowly changing.
Analysis will be preformed at a monthly frequency.
For these reason the standard analytic architecture of acquisition layer, integration / modeling layer and access layer make sense. What has been discussed thus far is the acquisition process and some components of the integration / modeling layer. Further modeling takes place creating attributes to be used in forecasting returns. These attributes are created using transformations such as residuals from cross sectional regression (to assess valuation), and rolling return and volatility estimation. Other techniques will be used too. Due to the complexity of these types of transformations they are performed in R and Python. I’m not going to cover this now, but point out that this extra layer of modeling occurs before data is written to fact tables in the access layer. Documentation of these processes can wait until another post.
Planned functionality
This thing will be ever evolving. The immediate plans for additional functionality relate to manual overlays. The idea here is to allow input of missing data. For example, a common issue is share count data missing or incorrectly quoted (we see counts quoted in both millions and thousands). Building logic to capture and correct this can be tricky. It is easier to manually capture and insert as an overlay to the raw SEC data.
Wrapping up
So that gives a brief outline of how I’m loading data into the acquisition layer of my database. We also covered some of the initial standardisation and integration steps. The next step is transforming that data into features that will ultimately be used for predictive modeling.
The repo has further details on the project.
This post is a little light on visualisation and code. To showcase the data collected I’ll finish up with a couple of plots. One using the price data and one the fundamental data. The first looks at the skewness effect and the next, the relation between return on assets and future returns. These are taking data directly from the database.
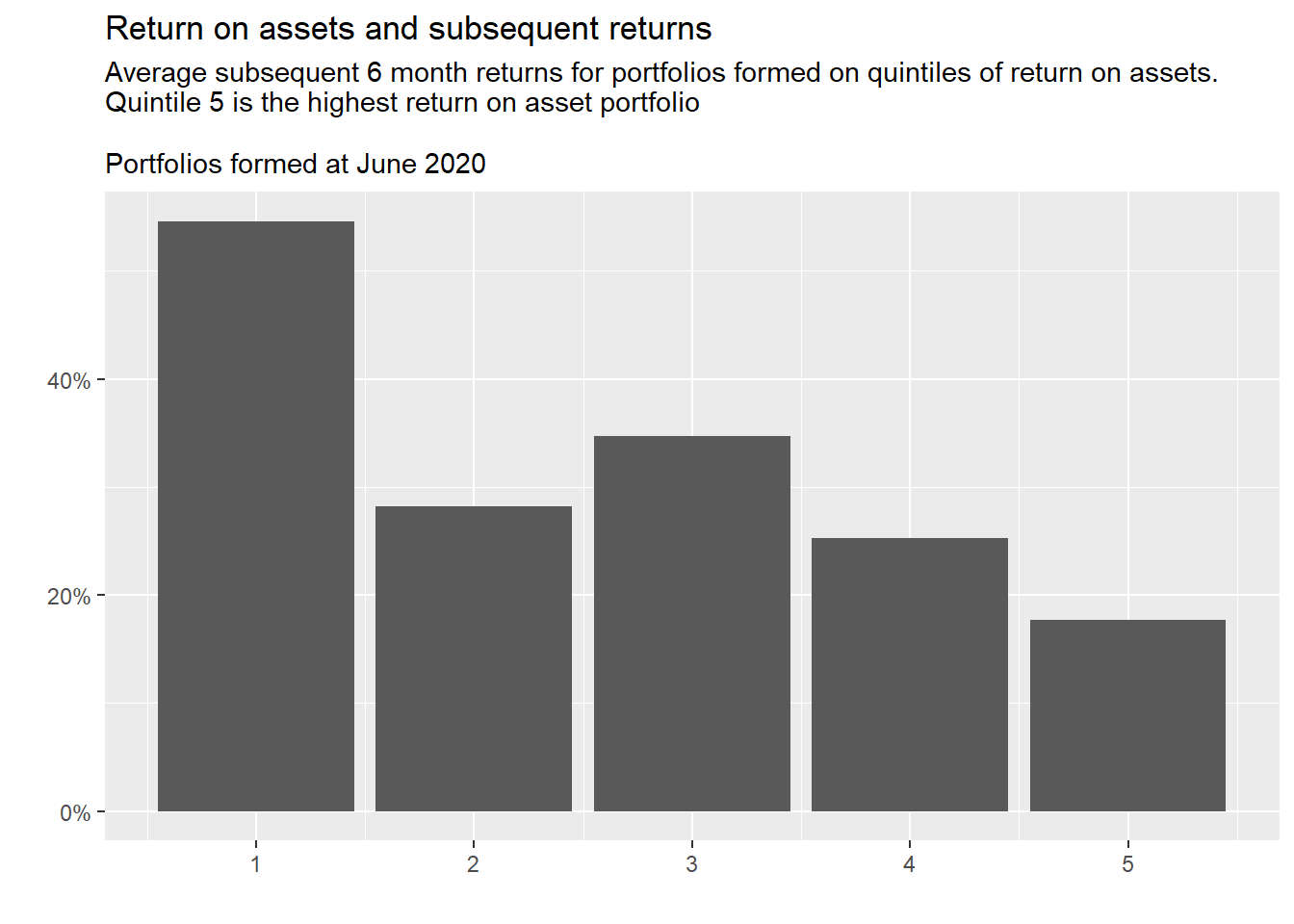
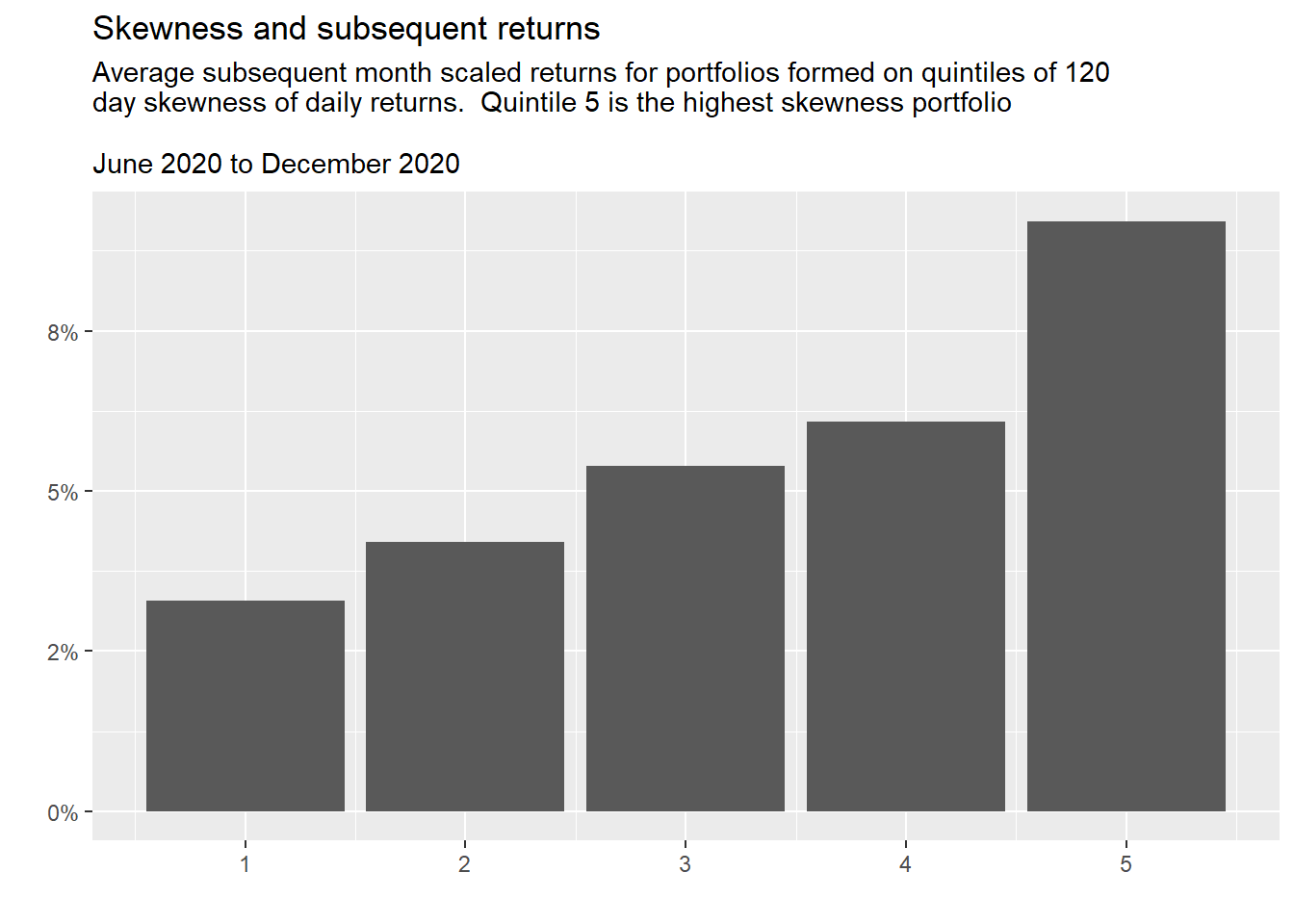
Example scripts and functions
SEC download script
##############################################################################
#
# Script extracting data from SEC website
# at https://www.sec.gov/dera/data/financial-statement-data-sets.html
#
##############################################################################
password = ''
# Libraries
from sqlalchemy import create_engine, MetaData, Table, text
import psycopg2
import pandas as pd
import numpy as np
import datetime as dt
import requests
import os
import io as io
from zipfile import ZipFile
# Create list of URL's for dates required
# Note that t2020 Q1 is under a different url
# https://www.sec.gov/files/node/add/data_distribution/2020q1.zip
# url_list = ['https://www.sec.gov/files/node/add/data_distribution/2020q2.zip']
# Prior quarters
start_year = 2020
end_year = 2020
start_qtr = 4
end_qtr = 4
base_url = 'https://www.sec.gov/files/dera/data/financial-statement-data-sets/'
url_list = [base_url+str(y)+'q'+str(q)+'.zip'
for y in range(start_year, end_year+1)
for q in range(start_qtr,end_qtr+1)]
# Connect to postgres database
# ?gssencmode=disable' per https://stackoverflow.com/questions/59190010/psycopg2-operationalerror-fatal-unsupported-frontend-protocol-1234-5679-serve
engine = create_engine('postgresql://postgres:'+password+
'@localhost:5432/stock_master?gssencmode=disable')
conn = engine.connect()
meta = MetaData(engine)
meta.reflect(schema='edgar')
sub_stage = meta.tables['edgar.sub_stage']
tag_stage = meta.tables['edgar.tag_stage']
num_stage = meta.tables['edgar.num_stage']
# Dictionary for logging count of lines per file
zf_info_dict = {}
# Looped implementation
for url in url_list:
resp = requests.get(url)
zf = ZipFile(io.BytesIO(resp.content))
zf_files = zf.infolist()
# Extract the quarter from the url string
# Set this manually for current url which has differing length
qtr = url[66:72]
# Loop over text files in the downloaded zip file and read to individual
# dataframes. Exclude the readme & pre files.
zf_files_dict = {}
for zfile in zf_files:
if zfile.filename == 'readme.htm':
continue
if zfile.filename == 'pre.txt':
continue
# For the sub and num files
if zfile.filename != 'tag.txt':
zf_info_dict[zfile.filename+'_'+qtr] = len(zf.open(zfile.filename).readlines())-1
try:
zf_files_dict[zfile.filename] = pd.read_csv(zf.open(zfile.filename),
delimiter='\t', encoding='utf-8')
except UnicodeDecodeError:
print('{f}{q} is not a utf-8 file'.format(f=zfile.filename, q=qtr))
try:
zf_files_dict[zfile.filename] = pd.read_csv(zf.open(zfile.filename),
delimiter='\t', encoding='ISO-8859-1')
except UnicodeDecodeError:
print('{f}{q} is not a ISO-8859-1 file'.format(f=zfile.filename, q=qtr))
finally:
pass
finally:
pass
# Tag does not load properly, save locally in order to use (delimiter='\t|\n')
else:
zf_info_dict[zfile.filename+'_'+qtr] = len(zf.open(zfile.filename).readlines())-1
zf.extractall(members = ['tag.txt'])
try:
tag = pd.read_csv('tag.txt', delimiter='\t|\n', encoding='utf-8')
except UnicodeDecodeError:
print('{f}_{q} is not utf-8 encoding'.format(f=zfile.filename, q=qtr))
try:
tag = pd.read_csv('tag.txt', delimiter='\t|\n', encoding='ISO-8859-1')
except UnicodeDecodeError:
print('{f}_{q} is not ISO-8859-5 encoding'.format(f=zfile.filename, q=qtr))
else:
print('{f}_{q} opened with ISO-8859-1 encoding'.format(f=zfile.filename, q=qtr))
else:
print('{f}_{q} opened with utf-8 encoding'.format(f=zfile.filename, q=qtr))
finally:
os.remove('tag.txt')
# Extract to individual dataframes and unsure columns align to database
# table structure. Add column (sec_qtr) indicating the zip file data originates from.
# We are only loading specific columns from the sub file.
sub = zf_files_dict['sub.txt']
sub_cols_to_drop = ['bas1','bas2','baph','countryma','stprma','cityma',
'zipma', 'mas1','mas2','countryinc','stprinc','ein',
'accepted']
sub = sub.drop(sub_cols_to_drop, axis=1)
sub = sub[['adsh','cik','name','sic','countryba','stprba','cityba',
'zipba','former','changed','afs','wksi','fye','form','period','fy',
'fp','filed','prevrpt','detail','instance','nciks','aciks']]
sub['sec_qtr']=qtr
tag = tag[['tag','version','custom','abstract','datatype','iord','crdr',
'tlabel','doc']]
tag['sec_qtr']=qtr
num = zf_files_dict['num.txt']
num = num[['adsh','tag','version','ddate','qtrs','uom',
'coreg','value','footnote']]
num['sec_qtr']=qtr
# Clear table contents (this is redundent if 'to_sql' specifies replace)
conn.execute(sub_stage.delete())
conn.execute(tag_stage.delete())
conn.execute(num_stage.delete())
# Insert to postgres database
sub.to_sql(name='sub_stage', con=engine, schema='edgar',
index=False, if_exists='append', method='multi', chunksize=50000)
tag.to_sql(name='tag_stage', con=engine, schema='edgar',
index=False, if_exists='append', method='multi', chunksize=50000)
num.to_sql(name='num_stage', con=engine, schema='edgar',
index=False, if_exists='append', method='multi', chunksize=50000)
print('{} pushed to DB'.format(qtr))
# Push to bad data and "final" tables
sql_file = open("edgar_push_stage_final.sql")
text_sql = text(sql_file.read())
conn.execute(text_sql)
print('{} pushed to final tables'.format(qtr))
# Close zip
zf.close()
# Save log file
log = pd.DataFrame.from_dict(zf_info_dict, orient='index', columns=['line_count'])
log.to_csv('log.csv')
# Close connection
conn.close()SEC data standardisation
create or replace view edgar.edgar_fndmntl_all_vw as
with t1 as
(
select
sb.name as stock
,nm.ddate
,nm.adsh
,sb.instance
,sb.cik
,sb.sic
,nm.sec_qtr
,sb.fy
,substring(sb.fp,2,1) as qtr
,nm.qtrs
,sb.filed
,nm.tag
,lk_t.lookup_val3 as level
,lk_t.lookup_val4 as L1
,lk_t.lookup_val5 as L2
,lk_t.lookup_val6 as L3
,nm.value/1000000 * lk_t.lookup_val1::int as amount
,case
when lk_s.lookup_val2 = 'Office of Finance' then 'financial'
else 'non_financial' end as fin_nonfin
from edgar.num nm
inner join edgar.lookup lk_t
on nm.tag = lk_t.lookup_ref
and lk_t.lookup_table = 'tag_mapping'
left join edgar.sub sb
on nm.adsh = sb.adsh
left join edgar.lookup lk_s
on sb.sic = lk_s.lookup_ref::int
and lk_s.lookup_table = 'sic_mapping'
where 1 = 1
-- Filter forms 10-K/A, 10-Q/A, these being restated filings
-- This should be done with sb.prevrpt however this was attribute removed pre insert
and sb.form in ('10-K', '10-Q')
-- coreg filter to avoid duplicates
and nm.coreg = 'NVS'
-- Filer status filter return only larger companies
-- refer to notes in edgar_structure.xlxs and 'https://www.sec.gov/corpfin/secg-accelerated-filer-and-large-accelerated-filer-definitions'
and sb.afs = '1-LAF'
)
,t11 as
( -- The mappings in edgar.lookup capture shares o/s as 'CommonStockSharesOutstanding'
-- this is not always populated. Grab 'EntityCommonStockSharesOutstanding'
select
adsh as t11_adsh
,avg(value/1000000) as l1_ecso
from edgar.num
where tag = 'EntityCommonStockSharesOutstanding'
and coreg = 'NVS'
group by 1
)
,t12 as
( -- The mappings in edgar.lookup capture shares o/s as 'CommonStockSharesOutstanding'
-- and that per t11 above are not always populated. Grab 'WeightedAverageNumberOfSharesOutstandingBasic'
select
adsh as t12_adsh
,ddate
,avg(value/1000000) as l1_wcso
from edgar.num
where tag = 'WeightedAverageNumberOfSharesOutstandingBasic'
and qtrs in (1,4) -- for non-year ends the quarterly average is disclosed, for year ends only the yearly average (test case FB)
and coreg = 'NVS'
group by 1,2
)
,t2 as
(
select
stock
,cik
,sic
,ddate
,adsh
,instance
,fy
,qtr
,qtrs
,filed
,sec_qtr
,fin_nonfin
,sum(case when level = '1' and L1 = 'a' then amount else 0 end) as L1_a
,sum(case when level = '1' and L1 = 'l' then amount else 0 end) as L1_l
,sum(case when level = '1' and L1 = 'le' then amount else 0 end) as L1_le
,sum(case when level = '1' and L1 = 'cso' then amount else 0 end) as L1_cso
-- ,sum(case when level = '1' and L1 = 'ecso' then amount else 0 end) as L1_ecso -- do not use, introduces newer date throwing partition filter in t4
,min(case when level = '1' and L1 = 'p' then amount else 0 end) as L1_p_cr
,max(case when level = '1' and L1 = 'p' then amount else 0 end) as L1_p_dr
,max(case when level = '2' and L2 = 'ca' then amount else 0 end) as L2_ca
,sum(case when level = '2' and L2 = 'nca' then amount else 0 end) as L2_nca
,sum(case when level = '2' and L2 = 'cl' then amount else 0 end) as L2_cl
,sum(case when level = '2' and L2 = 'ncl' then amount else 0 end) as L2_ncl
,min(case when level = '2' and L2 = 'eq' then amount else 0 end) as L2_eq_cr
,max(case when level = '2' and L2 = 'eq' then amount else 0 end) as L2_eq_dr
,max(case when level = '3' and L3 = 'cash' then amount else 0 end) as L3_cash
,sum(case when level = '3' and L3 = 'st_debt' then amount else 0 end) as L3_std
,min(case when level = '3' and L3 = 'lt_debt' then amount else 0 end) as L3_ltd
,sum(case when level = '3' and L3 = 'intang' then amount else 0 end) as L3_intang
,sum(case when level = '3' and L3 = 'depr_amort'then amount else 0 end) as L3_dep_amt
from t1
where 1 = 1
group by 1,2,3,4,5,6,7,8,9,10,11,12
)
,t3 as
(
select
t2.*
,rank() over (partition by adsh order by ddate desc) as rnk
,L1_a + L1_le as L1_bs_chk
,L1_a - L2_ca - L2_nca as L2_a_chk
,L1_l - L2_cl - L2_ncl
- (case when L2_eq_cr < 0 then L2_eq_cr else L2_eq_dr end) as L2_l_chk
,l2_ca + l2_nca + l2_cl + l2_ncl
+ (case when L2_eq_cr < 0 then L2_eq_cr else L2_eq_dr end) as L2_bs_chk
,case when L2_eq_cr < 0 then L2_eq_cr else L2_eq_dr end as L2_eq
,case when L1_p_cr < 0 then L1_p_cr else L1_p_dr end as L1_p
from t2
)
,t4 as
(
select
t3.*
,case when L1_bs_chk = 0 then L1_a else 0 end as total_assets
,case
when L1_bs_chk = 0 and L1_l != 0 then L1_l
when L2_cl != 0 and L2_ncl != 0 then L2_cl + L2_ncl
when L2_cl != 0 and L2_ncl = 0 and l2_eq != 0 then l1_le - l2_eq
else 0 end as total_liab
,case
when L1_bs_chk = 0 and L1_l != 0 then -(L1_a + L1_l)
when L2_cl != 0 and L2_ncl != 0 then -(L1_a + L2_cl + L2_ncl)
when L2_cl != 0 and L2_ncl = 0 and l2_eq != 0 then l2_eq
else 0 end as total_equity
,case when L1_bs_chk = 0 then L1_le else 0 end as total_liab_equity
,L1_cso as shares_cso
,case
when qtrs = 0 then 'pit'
when qtrs::text = qtr or (qtrs::text = '4' and qtr = 'Y') then 'ytd_pl'
else 'na'
end as bal_type
from t3
where rnk = 1
and case
when qtrs = 0 then 'pit'
when qtrs::text = qtr or (qtrs::text = '4' and qtr = 'Y') then 'ytd_pl'
else 'na'
end != 'na'
)
,t5 as
(
select
t4.*
,case
when L2_a_chk = 0 then L2_ca
when L2_ca <= total_assets and L2_ca != 0 then L2_ca
when L2_ca = 0 and L2_nca != 0 then total_assets - L2_nca
else total_assets
end as total_cur_assets
,case
when L2_a_chk = 0 then L2_nca
when L2_nca <= total_assets and L2_nca != 0 then L2_nca
when L2_nca = 0 and L2_ca != 0 then total_assets - L2_ca
else 0
end as total_noncur_assets
,case
when L2_l_chk = 0 then L2_cl
when L2_cl >= total_liab and L2_cl != 0 then L2_cl
when L2_cl = 0 and L2_ncl != 0 then total_assets - L2_ncl
else total_liab
end as total_cur_liab
,case
when L2_l_chk = 0 then L2_ncl
when L2_ncl >= total_liab and L2_ncl != 0 then L2_ncl
when L2_ncl = 0 and L2_cl != 0 then total_liab - L2_cl
else 0
end as total_noncur_liab
,L1_p - case when bal_type = 'ytd_pl' and qtrs > 1
then lag(L1_p) over (partition by cik, bal_type order by ddate)
else 0
end as net_income_qtly
from t4
)
,t6 as
(
select
t5.*
,case
when L3_cash <= total_cur_assets and L3_cash > 0 then L3_cash
else 0
end as cash_equiv_st_invest
,case
when L3_std >= total_cur_liab and L3_std < 0 then L3_std
else 0
end as st_debt
,case
when L3_ltd >= total_noncur_liab and L3_ltd < 0 then L3_ltd
else 0
end as lt_debt
,case
when L3_intang <= total_assets and L3_intang > 0 then L3_intang
else 0
end as intang_asset
from t5
)
,t7 as
(
select
stock
,cik
,sic
,ddate
,t6.adsh
,instance
,fy
,qtr
,filed
,sec_qtr
,fin_nonfin
,(date_trunc('month',filed) + interval '3 month - 1 day')::date as start_date
,sum(cash_equiv_st_invest) as cash_equiv_st_invest
,sum(total_cur_assets) as total_cur_assets
,sum(intang_asset) as intang_asset
,sum(total_noncur_assets) as total_noncur_assets
,sum(total_assets) as total_assets
,sum(st_debt) as st_debt
,sum(total_cur_liab) as total_cur_liab
,sum(lt_debt) as lt_debt
,sum(total_noncur_liab) as total_noncur_liab
,sum(total_liab) as total_liab
,sum(total_equity) as total_equity
,sum(net_income_qtly) as net_income_qtly
,round(sum(shares_cso),3) as shares_cso
from t6
group by 1,2,3,4,5,6,7,8,9,10,11,12
)
select
t7.*
,round(coalesce(t11.l1_ecso, t12.l1_wcso),3) as shares_ecso
from t7
left join t11
on t7.adsh = t11.t11_adsh
left join t12
on t7.adsh = t12.t12_adsh
and t7.ddate = t12.ddate
;I should note that other transforms will be done outside the database, and then written back. Estimating cross sectional regressions and calculating rolling volatility for example. Talking about this is for another day.↩︎
Fundamental data refers to accounting balances recorded in a company’s financial statements (the balance sheet, income statement and cash-flows). Price data of course is the traded share price.↩︎
There are other ways to do this. The developer of the Rank & Filed site mentioned above has developed a Python library which does this using if/else logic. I like the flexibility that a lookup table brings.↩︎